8 Expert Tips to Build Winning SEO Strategy
If you are going to publish content on your website, you might as well take time to ensure Google takes notice of your efforts. But, how to do that?
Most of you guys might have heard about the three-letter term “SEO” thrown around about Digital marketing, internet circles, and online businesses. But, do you understand what they mean?
Remember, instead of just creating what you think people are searching for, an SEO strategy makes sure that you are creating content that people are looking for. That is why to build winning SEO strategy is important to stay on track when creating content.
Today, we are going to learn everything about Search Engine Optimization to carry out a strong, and effective SEO strategy. We are going to cover:
-
- What is SEO?
- Importance of SEO Strategy
- 8 Expert Ways to Build Winning SEO Strategy
What Is SEO?
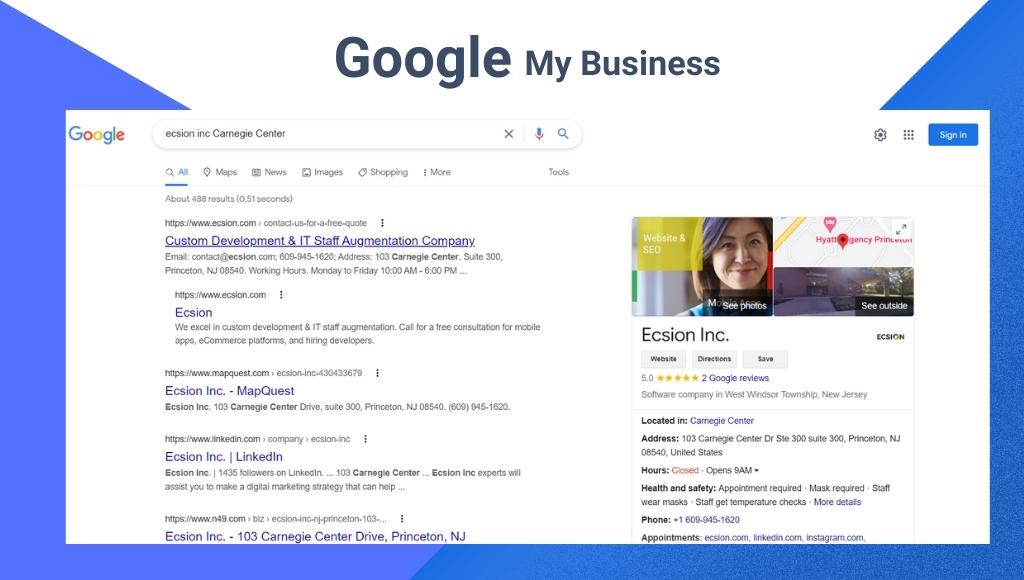
Nowadays, people turn to Google to find out answers to pretty much all doubts or queries. Business owners everywhere do whatever they can to make their site, and information findable on Google search. This is exactly what SEO is – the practice of optimizing your content to appear first on SERPs.

Search engine optimization is a process of optimizing websites to rank higher on Google search engine result pages through organic searches. SEO strategy is one of the fundamental strategies for any business to maximize the opportunity to gain organic traffic from search engines. It helps you discover opportunities to answer queries people have about their responsive business industry.
There are 3 types of Search engine optimizers:
-
On-page SEO
It focuses on content that’s actually on your website, and how to optimize it to increase the website ranking for specified keywords.
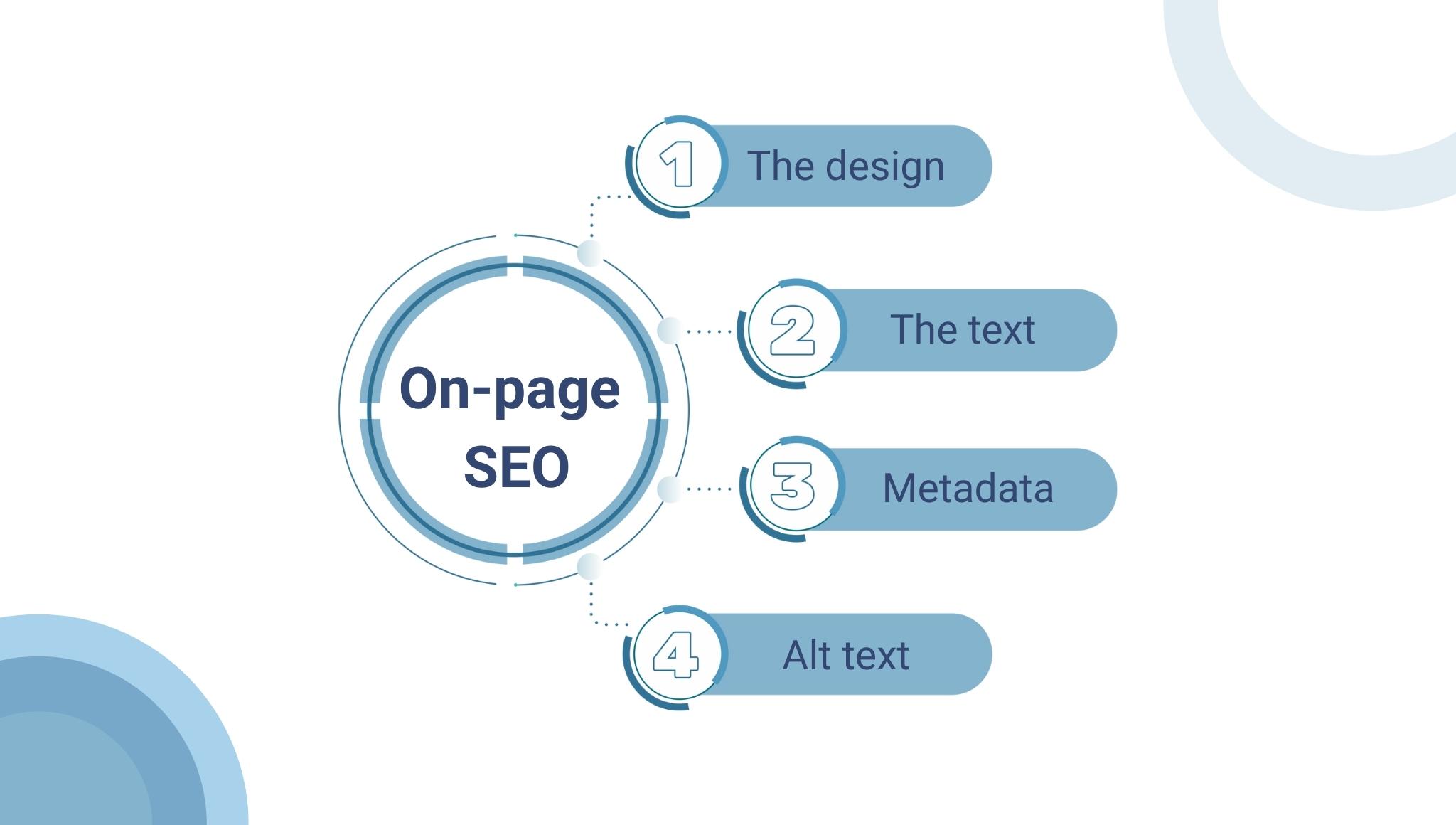
In simple words, on-page SEO is the strategy that you implement on your website.
For example,
-
- The design
- The text
- Metadata
- Alt text
-
Off-page SEO
It focuses on links directed to your site from elsewhere on the internet.
Incoming links or backlinks coming from reputable sources help your site to build trust with search algorithms.
For example,
-
- Social posts
- External links
- Other promotional methods
-
Technical SEO
It focuses on the website’s backend architecture. Every business has different goals depending on its business size.

SEO’s job is to examine their industry and identify what their audiences are looking for and establish a solid strategy to give them what they are searching for.
Importance Of SEO
-
- SEO is a budget-friendly marketing strategy than paid advertising
- It is more effective and longer-lasting
- It provides increases higher quality organic traffic and drives sales
- It improves visibility, credibility, and trust
- It provides higher ROI than other marketing channels
- Provides customer insight and sustainability
- Improves usability and user experience (UX)
- Builds a positive online reputation and increases domain authority of your website
8 Tips To Build Winning SEO Strategy
Every business should invest time in building a strong website strategy. It helps in increasing organic traffic to your site which is a crucial part of a digital marketing plan if you are looking for longevity and cost-effectiveness. Organic search driven by SEO strategies is unbeatable. Initially, SEO can feel like a slow burn, but the effects are long-lasting. A website is the anchor of your marketing efforts.
So, you cannot understate the importance of having an effective website for your business.
Now let us learn how to build a winning SEO strategy in 8 steps:

-
Write for people first and Google second
Google algorithm is getting smarter every day and uses constant human inputs to better align with your thought process. Being said that, there is no special mix to outwit a search engine, so it’s better to write for humans first than search engines.
Ultimately, your objective is to provide naturalistic content to your audience. Discover the right keywords to find the right audience to find you and elevate your already informative and valuable content.
-
Establish your top 3-5 goals
Identify your business goals and order them in priority. It is important to find out why you are creating a website. Having a site that has clearly defined goals is the key to setting yourself up for a successful business journey. Take some time to think about whether you are trying to increase sales of your products, you are trying to increase your SEO or you are trying to convert visitors to leads before developing your website.
-
Create a list of keywords
Keyword research is a legit SEO strategy for building a killer website. One of the best ways to find the right keyword is that which your users search. Google suggest – start typing a keyword into Google search and you will get a drop-down list of suggestions. This list can make great keywords for SEO strategy as it is directly populated by Google, and Google provides this list based on what people are searching for.
Long-tailed keywords are less competitive than short-tailed keywords, but they have low search volumes, and they are much easier to rank for. You can use different keyword search tools to discover the search volumes and competition of those terms to rank first on SERPs.
-
Focus on customer experience
Improved customer experience and usability have a direct correlation with their perception of your business. There is nothing worse than customers not using your website. A bad user experience will deeply harm your organic traffic. In fact, after more than a few seconds of frustration customers leave your website. To avoid such situations, you must immediately remove dead links, and error pages, and modify the messy website structure.
Google crawlers scan your content and determine your search engine ranking. Easy navigation and good customer experience allow Google to rank your website higher in SERPs.
Key focal points to remember for providing a seamless UX:
-
- Utilize heading and short
- Utilize easy-to-read paragraphs
- Tidy up your sub-folders
- Reduce page loading time
- Optimize your website for mobile devices
All these points will help you to reduce the bounce rate, improve your rankings, and generate a better conversion rate. Loading, Interactivity, and visual stability are the 3 core web vitals that have become a ranking factor through page experience updates. So, you should be optimizing page speed more than ever before. A positive user experience has a direct impact on how successful your business will be. Businesses that actively work on UX can control their brand reputation online to some degree.
-
Focus on relevant links
One of the key aspects of building the domain reputation or domain authority of your website is link-building. External links are important as it enhances the information that you are providing and also receive reciprocal incoming links through outreach. Google crawlers scan and discover content by following these links through subsequent pages and judge how related they are to a search query. You can also link useful pages to your website wherever and whenever required. Link-building attracts inbound links from other sources online.
You can approach different blogs for guest blogging opportunities through which can link back to your site. Websites with high domain authority that link back to your content have a more significant impact on your SEO strategies. Many marketers noticed an impact after a few months of implementing a link-building plan.
-
Remove anything that slows down your site
While writing informative blogs, selling your services, or pointing someone in the right direction, your site needs to be quick, accessible, and easy to use. Nowadays users expect instant access and instant results. If your website’s page load time is more, your customers will simply move.
Some of the ways to improve your site speed and the overall smoothness of your customer experience:
-
- Delete old or defunct plugins
- Clean up your code
- Compress your images
- Ensure that your sub-folders flow and make sense
- Use tools to monitor your website performance metric (GTmetrix or Google page speed insights)
-
Compress media files before uploading
As your website grows, you will have more content more images, videos, texts, and other relevant media to support your content. These visual files can be appealing to your visitors, but they can be very large in size. Since page loading time is an important factor in SEO strategy, it’s important to monitor the size of the media files before uploading them to your website.
Bigger file sizes may lead to reduced page speed. It’s harder for mobile browsers to load these heavy files as the bandwidth on mobile devices is significantly smaller. So, the smaller the file size, the faster your website will load.
-
Track your content’s success
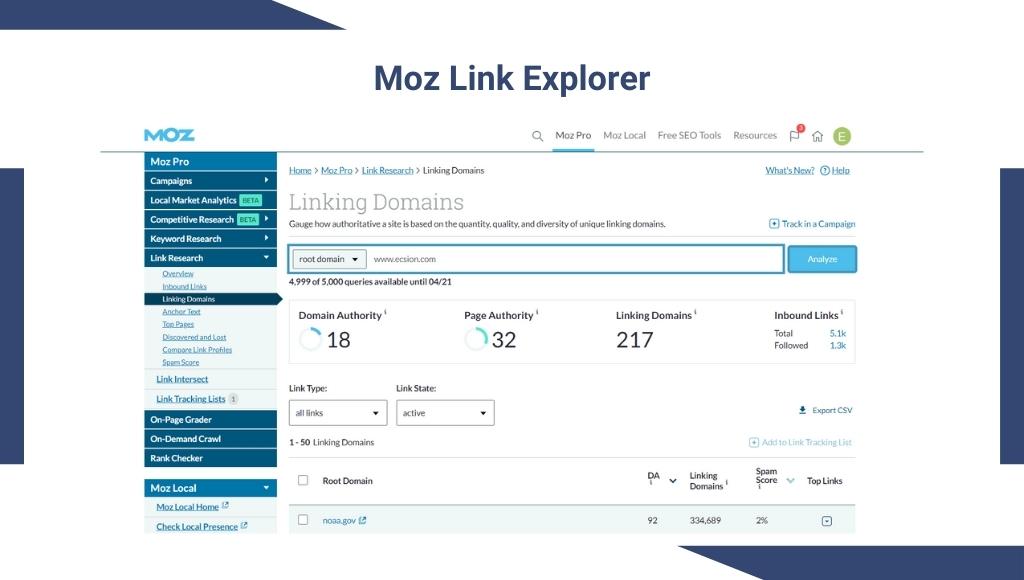
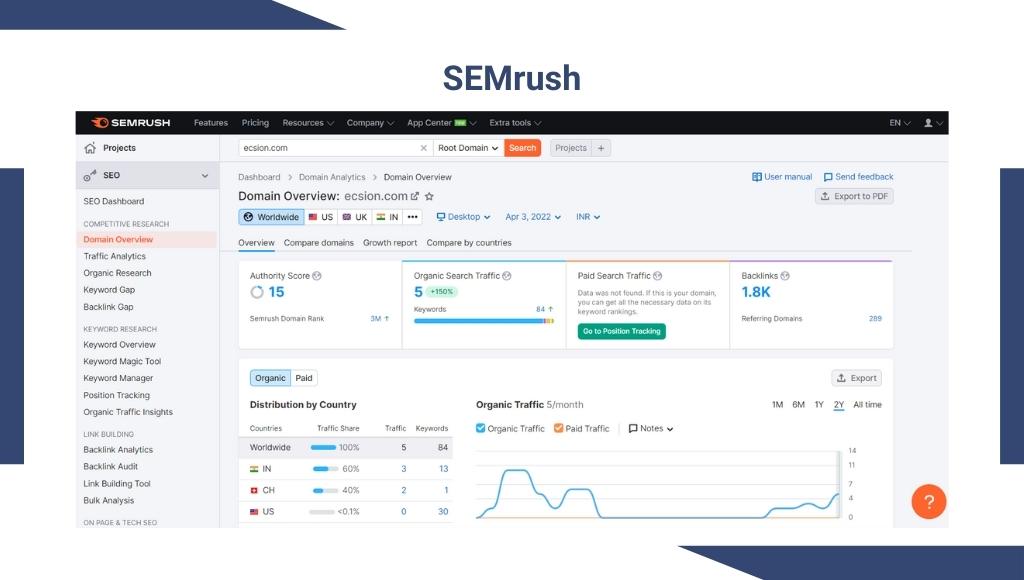
Search engine optimization strategies require patience and a lot of hard work to achieve your goals. It’s very important to monitor your metrics to understand the success and overall progress to build winning SEO strategy. It helps you to identify the areas of improvement. Organic traffic can be monitored by using various web analytics tools or by creating your own dashboard using Google sheets or excel.
Tracking the overall process including conversion rate, ROI, and your ranking on search engine result pages can help you recognize your success as well as determine the areas of opportunity.
The search engine landscape is ever-evolving. Staying up-to-date about the current trends and best practices is a crucial strategy plan for SEO.

How to calculate and optimize conversion rate for a website business is the question that is frequently asked by those Read more

What Is A Blog? A blog is an online journal or informational website displaying information in reverse chronological order. In Read more

We all know that search engines like Google, Bing, or Yahoo are serving millions of users per day who are Read more

If you are looking to start your own business, this article is for you. We will discuss here how to Read more